从输入 URL 到页面加载完毕
面试官常常会问我们 “用户输入 URL 回车之后发生了什么?”。实际上,这问题涵盖了网络和浏览器的许多知识点,是一个必须要掌握的概念。
大致步骤
在对每一个环节进行详细分析之前,我们先将这个过程列一个简单的草图:
- 用户输入
google.com(假设) 并按下回车。 - 浏览器查询 DNS。
- 建立 TCP 连接。
- 浏览器向服务器发送 HTTP 请求。
- 服务器处理请求并返回响应。
- 浏览器渲染页面。
第一步没啥好说的,我们下面从第二部开始进行详细的分析。
Notice
当前的讨论是基于 HTTP 请求下的,如果是 HTTPS,那么整个流程将会复杂得多的多。
浏览器查询 DNS
DNS 的主要目的是人性化导航,每一个域名都有一个分配给它的唯一 IP 地址,我们可以直接输入 IP 地址访问网站,但为了好记,大多数情况下是输入域名访问。
为了查找 DNS 记录,浏览器会检查四个缓存:
- 浏览器缓存:浏览器会缓存 DNS 记录一段固定的时间,不同浏览器时间不同(2~30 分钟),因为操作系统不会告诉浏览器每个 DNS 记录的生存时间。
- 操作系统缓存:浏览器检查操作系统缓存。如果它不在浏览器缓存中,浏览器将对您的底层计算机操作系统进行系统调用。操作系统会先查 hosts 件是否有记录,hosts 文件没有就去查本地 dns 解析器有没有缓存,如果有缓存就返回,没有就到下一步。
- 路由器缓存:请求继续发送到您的路由器,路由器通常有自己的 DNS 缓存。
- ISP 缓存:如果上面步骤都失败了,将转到 ISP 缓存。ISP 维护着自己的 DNS 服务器,其中包括一个 DNS 记录缓存,浏览器将检查这些缓存,以确保找到您请求的 URL。
ISP 查询 DNS
ISP 的 DNS 服务器会开始递归搜索,从根到顶级域名服务器,再到二级域名服务器以此类推。。。直到找到匹配的域名。
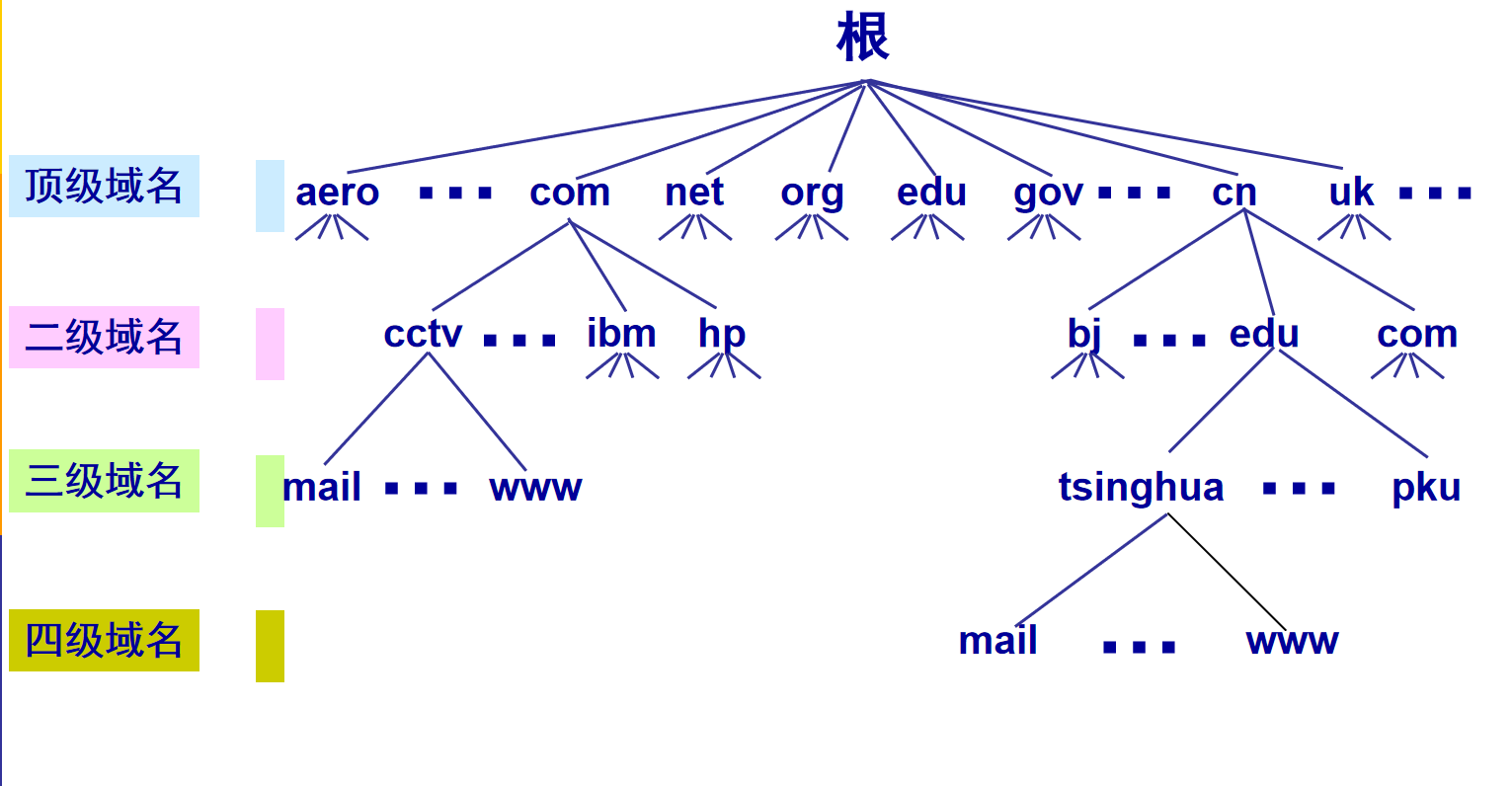
如 www.google.com,根服务器会找到 .com 域名服务器,接着重定向到 google.com 域名服务器,google.com 域名服务器将在 DNS 记录中找到 www.google.com 匹配的 IP 地址。
正因为一个域名对应一个 IP 地址,如果访问量太大怎么办?
有一些方法可以解决这个问题:
- DNS 轮询:DNS 服务器查找并返回多个 IP 地址而不只是一个。
- 负载均衡器:一种硬件,侦听特定的 IP 地址并把请求转发到其他服务器。
- 地理 DNS:通过根据客户端的地理位置将域名映射到不同的 IP 地址来提高可扩展性。
- 泛播(任意播):是一种路由技术,可以将单个 IP 地址映射到多个物理服务器。
建立 TCP 连接
一旦浏览器接收到正确的 IP 地址,它就会与匹配 IP 地址的服务器建立连接以传输信息。浏览器使用互联网协议来建立这样的连接。可以使用多种不同的 Internet 协议,但 TCP 是用于多种 HTTP 请求的最常用协议。
客户端与服务器建立 TCP 连接之前先要进行三次握手:
- 客户端向服务器发送 SYN 数据包,询问服务器是否打开新连接。
- 如果服务器有可以接受和发起新连接的开放端口,它将使用 SYN/ACK 数据包以 SYN 数据包的 ACK 作为相应。
- 客户端将收到来自服务器的 SYN/ACK 数据包,并通过发送 ACK 数据包进行确认。
然后建立 TCP 连接进行数据传输。
Notice
三次握手的目的是为了让服务器和客户端检验自己和对方的信息收发能力是否正常。
浏览器向服务器发送 HTTP 请求
TCP 连接建立成功后,浏览器将发送一个 GET 请求,请求获取 google.com 网页。
请求包含多个头部字段,如 User-Agent(浏览器标识)、Accept(接收的请求类型)、网站携带的 cookie 等等。
如下是一个 GET 请求示例:
GET http://google.com/ HTTP/1.1
Accept: ...
User-Agent: ...
Accept-Encoding: ...
Connection: ...
Host: ...
Cookie: ...
服务器处理请求并返回响应
正如我们看到的一样,我们的 GET 请求是发向 google.com 的,google.com 除了 www.google.com 也许有多个二级域名,浏览器怎么确定我们访问的是哪一个?服务器重定向。
当谷歌服务器接收到请求后会返回一个 301 重定向告诉浏览器去请求 http://www.google.com/ 而不是 http://google.com/。
而后浏览器会跟随重定向,向重定向的域名 http://www.google.com/ 发起新的 GET 请求。
随后服务器接收到请求并响应 200,响应体中的 Content-Encoding: gzip 表示响应体使用 gzip 算法压缩,解压缩之后就会得到真正的 HTML。
浏览器渲染页面
在我们成功获取到了页面的 html 文件后,浏览器会解析该文件。
Notice
浏览器的 Loader 模块有两条资源加载路径,主资源加载路径和派生资源加载路径。主资源加载主页 html 文件,派生资源加载 html 文件中引入的资源。
浏览器沿着 html 文件,自上而下进行构建。
解析 HTML,解析 CSS,解析 JS,加载外部资源,重绘和回流都运行在不同的线程中。
HTML 和 CSS 的解析是并行的,共同完成浏览器会将生成的 DOM 和 CSSOM 合并成渲染树,然后计算渲染树中每个元素的布局(layout),然后渲染(paint)到页面上。
JS 脚本由于可以访问 CSSOM,因此需要在 CSSOM 构建完成之后才执行。
关于这部分浏览器的渲染的详细过程,请看浏览器渲染原理
总结
- 输入 url 后,首先需要找到这个 url 域名的服务器 ip,为了寻找这个 ip,浏览器首先会寻找缓存,查看缓存中是否有记录,缓存的查找顺序为:浏览器缓存、操作系统缓存、路由器缓存、ISP 缓存(DNS 服务器)。
- 得到服务器的 ip 地址后,浏览器根据这个 ip 以及相应的端口号,构造一个 http 请求,这个请求报文会包括这次请求的信息,主要是请求方法,请求说明和请求附带的数据,并将这个 http 请求封装在一个数据包中,这个数据包会依次经过传输层,网络层,数据链路层,物理层,经过物理传输后再向上到达服务器,与服务器建立 tcp 连接。
- 服务器解析这个请求来作出响应,返回相应的 html 给浏览器,HTML 解析器将字符串解析成为一个个 token,根据 token 生成一个个 node,再将 node 根据嵌套结构生成 DOM 树,在 dom 树的构建过程中如果遇到 JS 脚本和外部 JS 连接,则会停止构建 DOM 树来执行和下载相应的代码,这会造成阻塞;同时,浏览器会根据解析的 css 样式表生成 CSSOM,最后将 CSSOM 和 DOM 合并成渲染树。然后根据渲染树计算元素的布局位置,在网页上渲染。因为 html 文件中会含有图片,视频,音频等资源,在解析 DOM 的过程中,遇到这些都会进行并行下载,浏览器对每个域的并行下载数量有一定的限制,一般是 4-6 个,下载这些资源的时候如果有缓存,还需要经过强制缓存、协商缓存的策略进行资源的获取。